

24時間365日、システムを止めずに運用し続けることが求められる現代。
特に金融や医療、インフラ分野では、一瞬の停止が大きな損失や人命に関わるリスクを招くこともあります。
 石田先生
石田先生こうした状況では、わずかなダウンタイムであっても信用の失墜や業務の混乱を引き起こすおそれがあるため、信頼性と継続性の確保が最優先されます。
そこで注目されるのが「HAクラスタ(High Availability Cluster)」です。
これは、複数のサーバを連携させることで、1台に障害が発生しても他のサーバが自動的に役割を引き継ぎ、システムを止めることなく継続運用を可能にする技術です。
この記事では、HAクラスタの基本的な仕組みや構成要素、さらには実際にどのような場面で活用されているかについて、初学者にもわかりやすく丁寧に解説していきます。
HAクラスタとは
HAクラスタ(High Availability Cluster)とは、システムの可用性(Availability)を高めるために、複数のサーバを連携させて一つのシステムのように動作させる仕組みです。
石田先生日本語では「高可用性クラスタ」と訳され、クラスタシステムとも呼ばれています。
特に高い信頼性や継続稼働が求められる分野で重宝されており、サーバが単体で動作するシステムに比べて、圧倒的に強固な障害対策が可能です。
サーバ1台に障害が起きてもサービスが停止しないという特徴は、停止が許されない現代の重要業務系システムにおいて非常に重要な要素です。
フェイルオーバーとハートビート
HAクラスタでは、あらかじめ複数のサーバ(ノード)を冗長構成にしておき、1台に障害が発生した場合でも他のサーバが業務を自動的に引き継ぐフェイルオーバー機構を備えています。
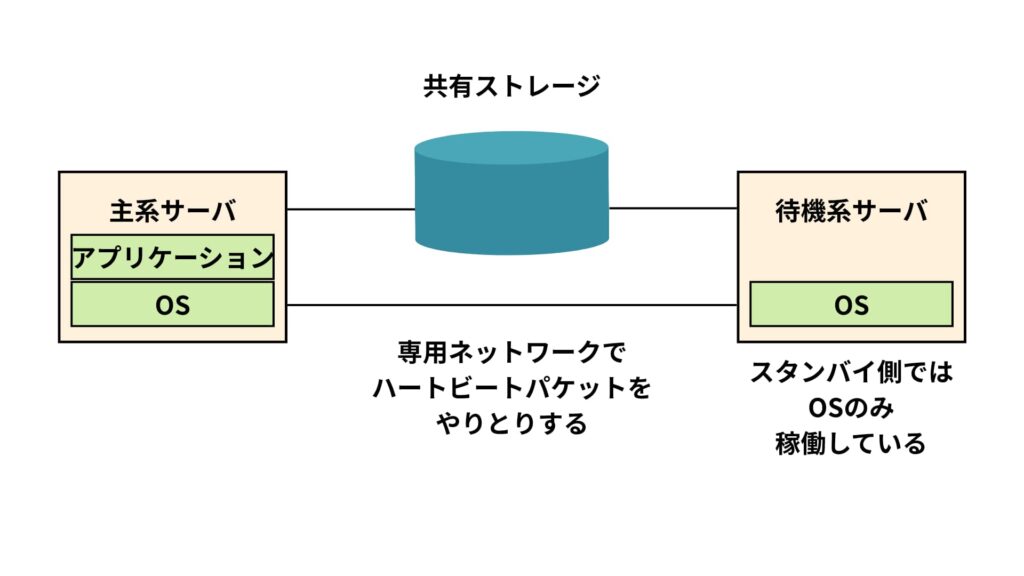
このフェイルオーバーを円滑に行うために、「ハートビートパケット」と呼ばれる定期的な信号の送受信によってノードの正常性を監視します。
ハートビートパケットの送信間隔は、HAクラスタ構成や使用するクラスタソフトウェア(たとえばPacemaker、Veritas Cluster Serverなど)によって異なりますが、一般的には次のような設定が多いです。
- 送信間隔(ハートビートインターバル):1秒〜10秒程度
- タイムアウト判定時間(監視タイムアウト):インターバルの3倍〜5倍が一般的(例:インターバルが2秒なら、6〜10秒で障害と判断)
この間隔は、可用性と誤検知のバランスで調整されます。たとえば重要なシステムでは1秒間隔で頻繁に確認し、できるだけ早く障害を検知・切り替えできるようにします。
この信号が一定時間途絶えた場合、該当ノードは「ダウン」と判断され、スタンバイ状態にあった別のサーバが自動的にアクティブノードとして稼働を開始します。
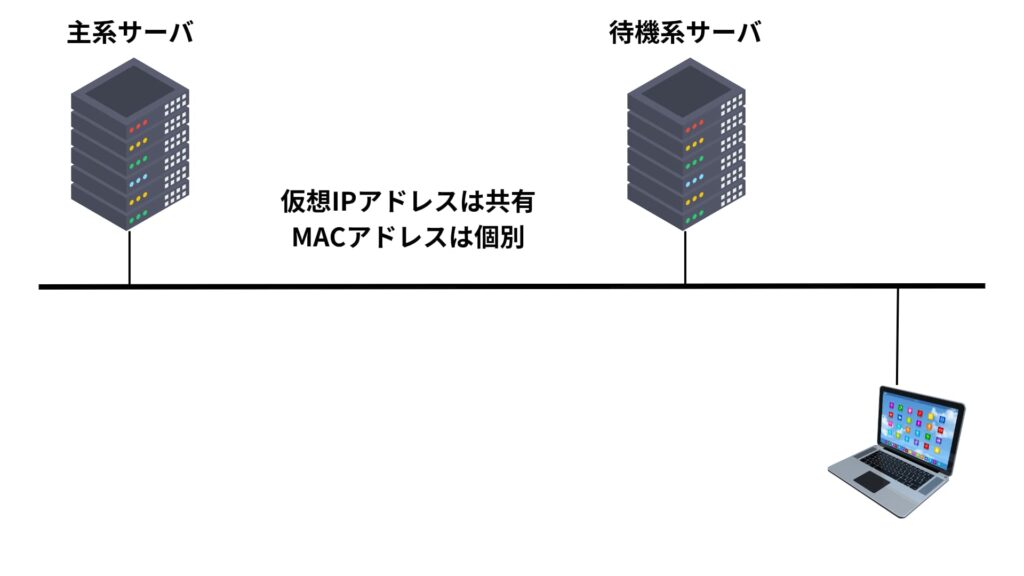
フェイルオーバー時には、サービスの継ぎ目のない引き継ぎが求められます。
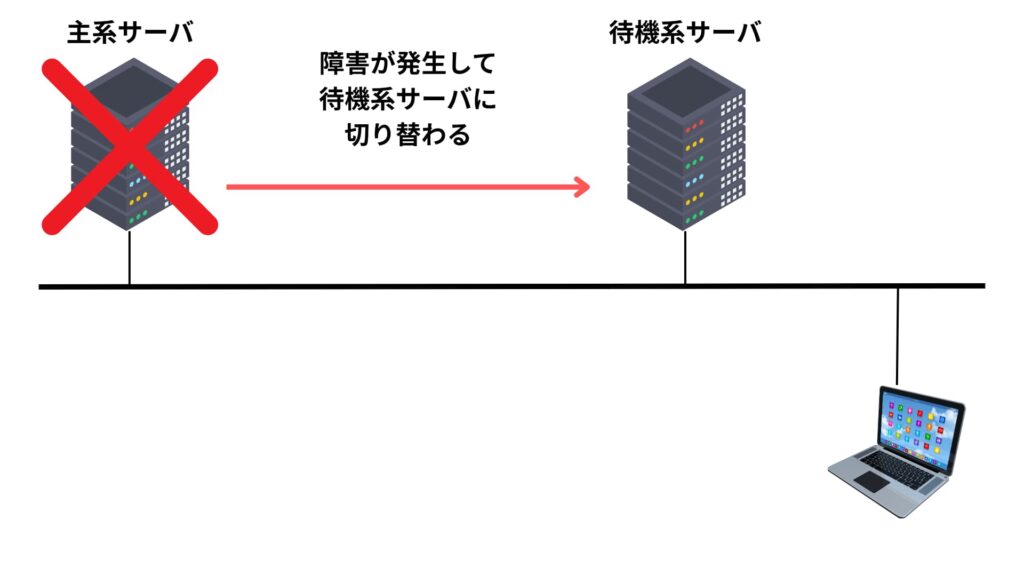
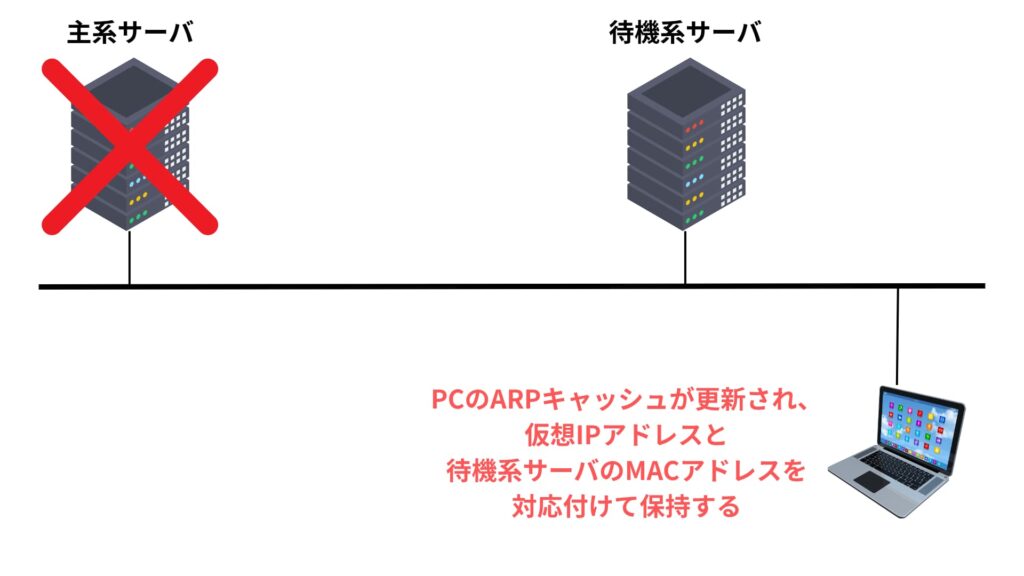
そのため、新たにアクティブとなるサーバが、これまで稼働していたサーバの仮想IPアドレスを引き継ぐことで、クライアント側からの接続先が変わらないようにします。
しかし、MACアドレスまでは引き継ぐことができないため、ネットワーク上に「Gratuitous ARP(グラチュイタスARP)」と呼ばれるブロードキャストを送信し、仮想IPアドレスと新しいMACアドレスとの対応関係を周囲の機器に通知します。
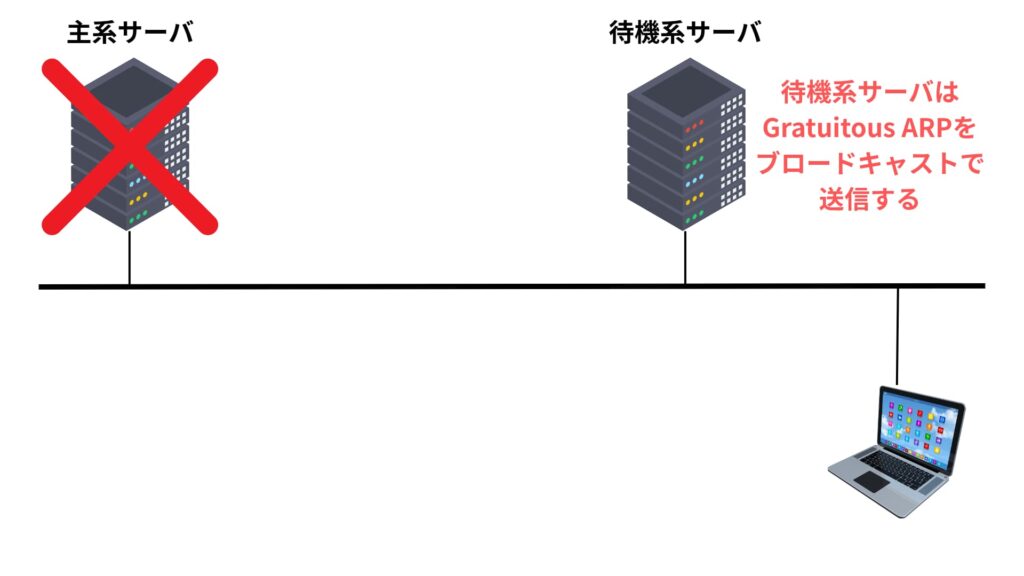
これにより、スイッチやルータなどが即座にMACアドレスを更新し、仮想IP宛の通信を新しいサーバに届けることが可能になります。
 石田先生
石田先生こうした切り替え処理は数秒から十数秒で完了するため、ユーザーはほとんど気づかずにサービスを利用し続けることができます。
仮想IPによる透過的な接続
さらに、HAクラスタでは複数のサーバが1つの「仮想IPアドレス(VIP)」を共有することが一般的です。
これにより、システムがどのノードで処理されているかにかかわらず、ユーザーは常に同じIPアドレスへアクセスできます。
この仮想IPへの通信は、クラスタ管理ソフトウェアによって自動的に稼働中のノードへと転送されるため、サービス利用者はサーバの切り替えや障害に一切気づくことがありません。
運用側にとっても、設定変更や接続先変更の手間が省けるというメリットがあります。
クラスタ構成の種類
クラスタ構成には大きく分けて「アクティブ-アクティブ構成」と「アクティブ-スタンバイ構成」の2種類があります。
アクティブ-アクティブ構成
アクティブ-アクティブ構成では、すべてのノードが同時に稼働し、リクエストや処理を分散して処理します。
この方式はパフォーマンスの最大化に優れていますが、すべてのノードに均等な設計と同期処理が求められるため、設計と運用に高度なスキルが必要です。
アクティブ-スタンバイ構成
一方、アクティブ-スタンバイ構成では、一部のノードだけが稼働し、残りのノードはフェイルオーバーに備えて待機します。
この待機ノード(スタンバイ)にはいくつかの運用レベルがあり、システムの重要性や復旧スピードの要件に応じて選択されます。
コールドスタンバイは、スタンバイノードの電源がオフになっている状態です。
障害発生後に電源を入れ、OSの起動やサービスの立ち上げを行うため、復旧に時間がかかりますが、平常時の消費電力やコストを抑えることができます。
あまり頻繁に障害が発生しないシステムや、すぐの復旧が求められない場面で用いられます。
ウォームスタンバイは、スタンバイノードの電源は入っており、OSも起動していますが、アプリケーションサービスは稼働していない状態です。
障害発生後は、必要なサービスを起動するだけで済むため、コールドスタンバイよりも復旧が速くなります。
バランスの取れた方式として、中規模なシステムでよく採用されます。
ホットスタンバイは、スタンバイノードもアクティブノードとほぼ同じ状態で常時稼働しており、サービスも起動した状態で待機しています。
フェイルオーバー時は瞬時に切り替えが可能で、ほとんどダウンタイムが発生しません。
そのため、特に厳格な可用性が求められるミッションクリティカルなシステムに適していますが、平常時のリソース消費や運用コストは高くなります。
スプリットシンドロームの問題
HAクラスタにおいて注意すべき現象のひとつが「スプリットシンドローム(スプリットブレイン)」です。
これは、クラスタ内の通信が断絶された際に、複数のノードが「自分こそが唯一のアクティブノードである」と誤認し、それぞれが同時にサービスを提供してしまう状態を指します。
石田先生通信断は物理的なネットワーク障害やスイッチ障害、ファイアウォールの設定ミスなど、さまざまな原因によって引き起こされる可能性があります。
このような状態になると、同じデータに対して複数のノードが処理を行ってしまい、データベースの整合性が失われたり、ファイルシステムが破損したりするなど、重大な障害につながるおそれがあります。
また、クラスタ全体の制御が混乱し、正常系と異常系の区別がつかなくなることで、システム全体の停止を招くケースも少なくありません。
特に厄介なのが、ハートビートパケットの遅延によって誤認が発生する場合です。
たとえば、ネットワーク混雑やパケットロスなどの影響で、ハートビートパケットの到着が遅れた場合、スタンバイ側のノードが「アクティブノードがダウンした」と勘違いして自らが稼働を始めてしまいます。
すると、同じ仮想IPアドレスを持つノードが複数同時にネットワーク上に存在することになり、ARPテーブルの混乱やセッションの分断、アプリケーションの誤作動などが発生します。
こうした誤認を防ぐためには、ハートビート通信を信頼性の高い専用ネットワーク上で行うことが重要です。
業務トラフィックとは物理的・論理的に完全に分離されたインターフェースを用意し、ネットワーク帯域の競合や遅延の影響を受けないようにすることで、フェイルオーバーの正確性が向上します。
加えて、複数経路の冗長化や、監視項目の多重化なども有効な手段です。
スプリットシンドロームを防ぐための対策
スプリットシンドロームの対策として代表的なものに、次の2つがあります。
- フェンシング(Fencing):障害の疑いがあるノードを強制的にネットワークやストレージから切り離し、他ノードとの同時稼働を防ぐ方法。STONITH(Shoot The Other Node In The Head)と呼ばれる手法が使われることもあります。
- クォーラム(Quorum):クラスタのノード数の過半数(多数派)で制御を行う仕組み。過半数に満たないノード群はサービスの提供を停止し、スプリットシンドロームを防ぎます。
これらの対策を適切に導入することで、HAクラスタにおける高可用性を維持しつつ、同時稼働のリスクを低減することができます。
まとめ
HAクラスタは、システム停止が許されない環境での信頼性確保において非常に有効な手段です。
障害時の自動切り替え、仮想IPの引き継ぎ、Gratuitous ARPによるMAC通知など、連携された仕組みによってユーザーに意識させることなくサービスを継続できます。
ただし、スプリットシンドロームのような予期せぬ障害が生じるリスクもあるため、フェンシングやクォーラム、専用ネットワークの設計など、多面的な対策が欠かせません。
適切な構成と運用によって、HAクラスタは「止まらないシステム」を実現する強力な技術となります。
業務継続性を求めるすべての現場で、その導入と活用が今後ますます重要になっていくでしょう。
