

問1 マルチクラウド利用による可用性向上に関する次の記述を読んで、設問に答えよ。
A社は、従業員500人のシステム開発会社である。A社では、IaaSを積極的に活用して開発業務を行ってきたが、利用しているIaaS事業者であるB社で大規模な障害が発生し、開発業務に多大な影響を受けた。A社のシステム部では、利用するIaaS事業者をもう1社追加してマルチクラウド環境にし、本社を中心にネットワーク環境も含めた可用性向上に取り組むことになり、Eさんを担当者として任命した。
現在のA社のネットワーク構成を図1に示す。
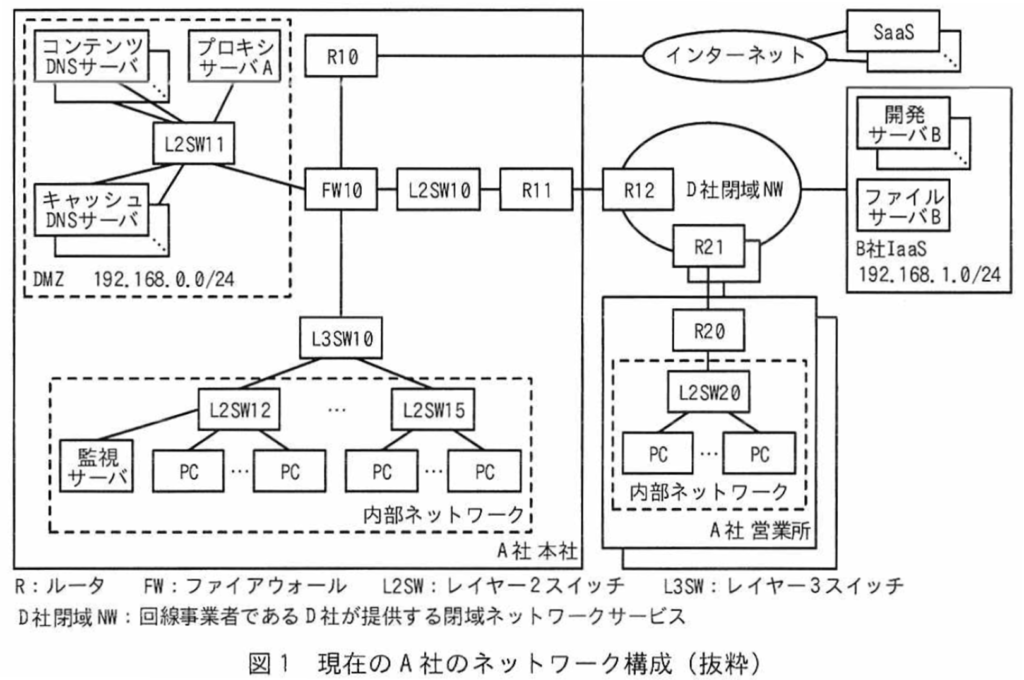
図1の概要を次に示す。
•A社は本社と2か所の営業所で構成されている。
•D社閉域NWを利用して、本社と2か所の営業所を接続している。R11及びR20といったA社とD社閉域NWとを接続するルータは、D社からネットワークサービスとして提供されている。
•D社閉域NWとB社IaaSは相互接続しており、A社はD社閉域NW経由でB社IaaSを利用している。
•A社ネットワークでは静的経路制御を利用している。
•B社からは、Webブラウザを利用した画面操作によって、IaaS上に仮想ネットワーク、仮想サーバを簡単に構築できる管理コンソールが提供されている。
•A社のシステム部は、受託した開発業務ごとに開発サーバBを構築し、A社の担当部門に引き渡している。開発サーバBの運用管理は担当部門で実施する。
•システム部は、共用のファイルサーバBを構築し、A社の全部門に提供している。
•A社の全部門で利用する電子メールやチャット、スケジューラーなどのオフィスアプリケーションソフトウェアはインターネット上のSaaSを利用している。これらのSaaSはHTTPS通信を用いている。
•A社の一部の部門では、担当する業務に応じてインターネット上のSaaSを独自に契約し、利用している。これらのSaaSでは送信元IPアドレスによってアクセス制限をしているものもある。これらのSaaSもHTTPS通信を用いている。
•プロキシサーバAは、従業員が利用するPCやサーバからインターネット向けのHTTP通信、HTTPS通信をそれぞれ中継する。従業員はプロキシサーバとしてproxy.a-sha.co.jpをPCのWebブラウザやサーバに指定している。
•A社は、本社設置のR10を経由してインターネットに接続している。FW10にはグローバルIPアドレスを付与しており、FW10を経由するインターネット宛ての通信はNAPT機能によってIPアドレスとポート番号の変換が行われる。
•キャッシュDNSサーバは、PCやサーバからの問合せを受け、ほかのDNSサーバへ問い合わせた結果を応答する。キャッシュDNSサーバは複数台設置されている。
•コンテンツDNSサーバは、PCやサーバのホスト名などを管理し、PCやサーバなどに関する情報を応答する。コンテンツDNSサーバは複数台設置されている。
•監視サーバは、ICMPを利用する死活監視(以下、ping監視という)を用いてDMZやIaaSにあるサーバの監視を行っている。監視サーバで検知された異常はシステム部の担当者に通知され、復旧作業などの必要な対応が行われる。
システム部では、ネットワーク環境の可用性向上の要件を次のとおりまとめた。
•新規にC社のIaaSを契約し、B社IaaSと併せたマルチクラウド環境にし、D社閉域NW経由で利用する。
•A社本社とD社閉域NWとの接続回線を追加し、マルチホーム接続とする。
•インターネット接続を本社経由からD社閉域NW経由に切り替える。
可用性向上後のA社のネットワーク構成を図2に示す。
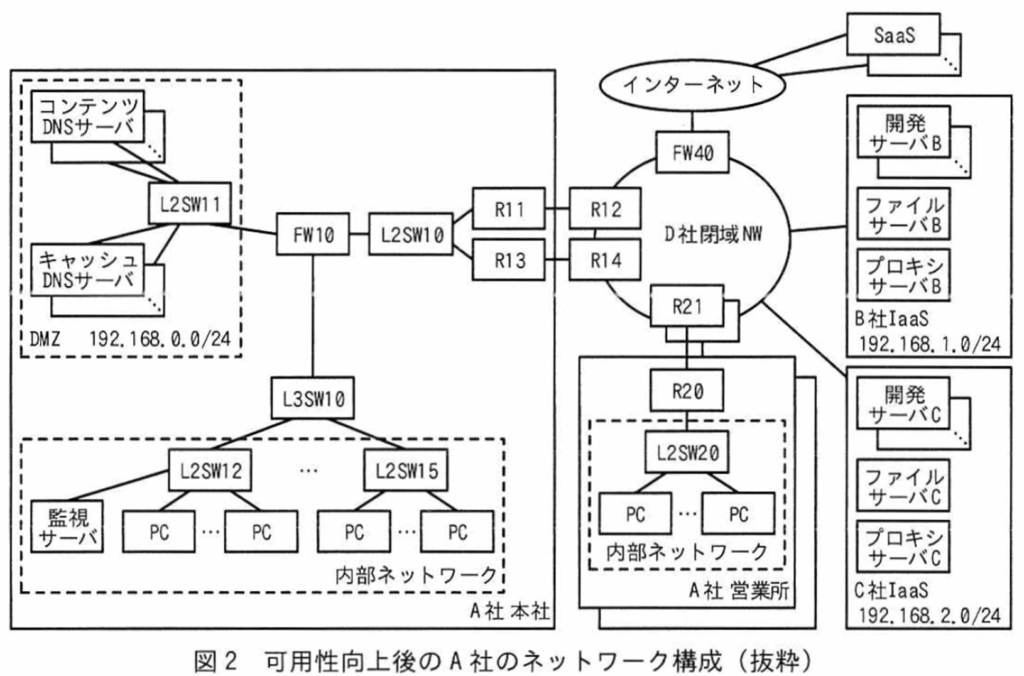
[B社とC社のIaaS利用]
C社からも、B社と同様に管理コンソールが提供されている。B社IaaSに構築された仮想ネットワーク、仮想サーバとC社IaaSに構築された仮想ネットワーク、仮想サーバはD社閉域NWを経由して相互に通信できる。
Eさんは、B社とC社のIaaS利用方針を次のとおり策定した。
•C社IaaSにファイルサーバCを新たに構築し、ファイルサーバBと常に同期をとるように設定する。A社従業員はファイルサーバB又はファイルサーバCを利用する。
•B社IaaSにプロキシサーバBを、C社IaaSにプロキシサーバCを新たに構築し、プロキシサーバAから切り替える。
•B社IaaSを利用して開発サーバBを、C社IaaSを利用して開発サーバCを構築し、A社の担当部門に引き渡す。
[プロキシサーバの利用方法の検討]
Eさんは、IaaSに構築するプロキシサーバBとプロキシサーバCの利用方法を検討した。プロキシサーバの利用方法の案を表1に示す。

Eさんは、従業員が利用するプロキシサーバを、DNSの機能を利用して制御することを考えた。プロキシサーバに障害が発生した際には、DNSの機能を利用して切り替える。
プロキシサーバに関するDNSゾーンファイルの記述内容を表2に示す。

Eさんは、プロキシサーバの監視運用について検討した。監視サーバで利用できる①ping監視では不十分だと考え、新たにTCP監視機能を追加し、プロキシサーバのアプリケーションプロセスが動作するポート番号にTCP接続可能か監視することにした。また、監視対象として、従業員がプロキシサーバとして指定するホストに加えて、プロキシサーバA、プロキシサーバB、プロキシサーバCのホストを設定することにした。
次に、監視サーバでプロキシサーバBの異常を検知した際に、従業員がプロキシサーバの利用を再開できるようにするための復旧方法として、②DNSゾーンファイルの変更内容を案1、案2それぞれについて検討した。また、③平常時からproxy.a-sha.co.jpに関するリソースレコードのTTLの値を小さくすることにした。
これらの検討の結果、プロキシサーバの負荷分散ができること、及びプロキシサーバの有効活用ができることから案2の方が優れていると考え、Eさんは案2を採用することにした。
さらに、Eさんは、自動でプロキシサーバを切り替えるために、④DNSとは異なる方法で従業員が利用するプロキシサーバを切り替える方法も検討した。プロキシサーバを利用する側の環境に依存することから、DNSゾーンファイルの書換えによる切替えと併用することにした。
[マルチホーム接続]
次に、EさんはD社閉域NWとのマルチホーム接続について検討した。A社本社に増設するルータ及び回線はD社からネットワークサービスとして提供される。マルチホーム接続の設計についてD社担当者から説明を受けた。
D社担当者から説明を受けたマルチホーム接続構成を図3に示す。
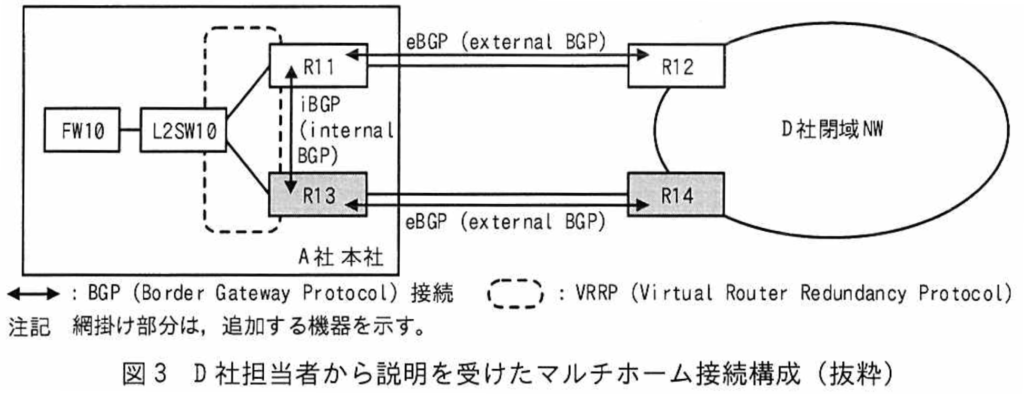
図3の概要は次のとおりである。
•本社とD社閉域NWとの間で、新たにR13と専用線がD社からネットワークサービスとして提供される。R11とR13とを併せてマルチホーム接続とする。
•増設する専用線の契約帯域幅は既設の専用線と同じにし、平常時は既設の専用線を利用し、障害発生時には増設する専用線を利用する。
•既存のR11とR12は、静的経路制御からBGPによる動的経路制御に変更する。
•R11とR12との間、R13とR14との間はeBGPで接続する。⑤R11とR13との間はiBGPで接続し、あわせてnext-hop-self設定を行う。
•R11とR13との間ではVRRPを利用する。FW10はVRRPで定義する仮想IPアドレスをネクストホップとして静的経路設定を行う。
D社担当者からの説明を受けたEさんは、BGPについて調査した。
RFC4271で規定されているBGPは、( a )間の経路交換のために作られたプロトコルで、TCPポート179番を利用して接続し、経路交換を行う。経路交換を行う隣接のルータを( b )と呼ぶ。BGPで交換されるメッセージは4タイプあり、表3に示す。

経路制御は、( c )メッセージに含まれるBGPパスアトリビュートの一つであるLOCAL_PREFを利用して行うとの説明をD社担当者から受けた。LOCAL_PREFは、iBGPピアに対して通知する、外部のASに存在する宛先ネットワークアドレスの優先度を定義する。BGPでは、ピアリングで受信した経路情報をBGPテーブルとして構成し、最適経路選択アルゴリズムによって経路情報を一つだけ選択し、ルータの( e )に反映する。LOCAL_PREFの場合では、最も( f )値をもつ経路情報が選択される。
また、Eさんは、D社担当者から静的経路制御からBGPによる動的経路制御に構成変更する手順の説明を受けた。この時、⑥BGPの導入を行った後にVRRPの導入を行う必要があるとの説明だった。Eさんが説明を受けた手順を表4に示す。

Eさんは、設計どおりにマルチホームによる可用性向上が実現できたかどうかを確認するための障害試験を行うことにし、⑨想定する障害の発生箇所と内容を障害一覧としてまとめた。
[インターネット接続の切替え]
次に、Eさんはインターネット接続を本社経由からD社閉域NW経由へ切り替えることについて検討した。
インターネット接続の切替え期間中の構成を図4に示す。
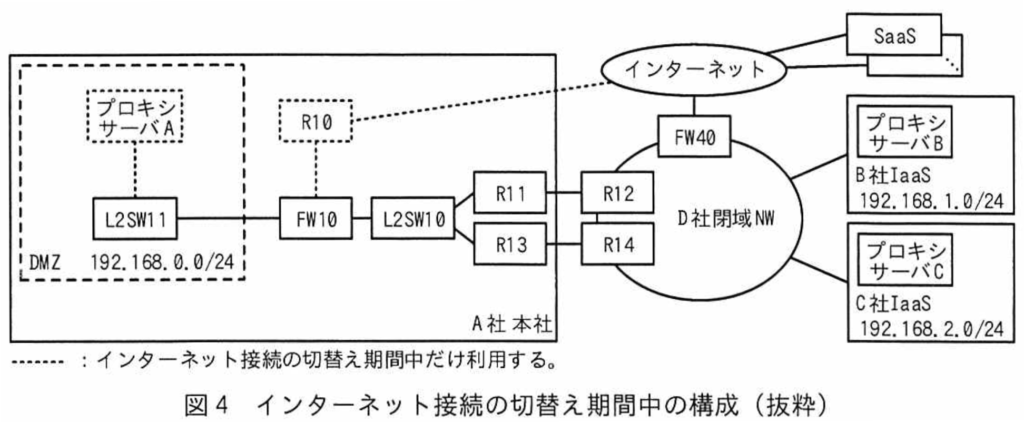
FW40を使ってインターネット接続する。FW40はD社からネットワークサービスとして提供される。FW40には新たにグローバルIPアドレスが割り当てられる。FW40を経由するインターネット宛ての通信はNAPT機能によってIPアドレスとポート番号の変換が行われる。A社とインターネットとの通信を、R10経由からFW40経由になるようにインターネット接続を切り替える。
Eさんは、設定変更の作業影響による通信断時間を極力短くするために、⑩FW10の設定変更はD社閉域NWの設定変更とタイミングを合わせて実施する必要があると考えた。
Eさんは、⑪インターネット接続の切替えを行うと一部の部門で業務に影響があると考えた。対策として、全てのインターネット宛ての通信はFW40経由へと切り替えるが、⑫一定期間、プロキシサーバAからのインターネット宛ての通信だけは既存のR10経由になるようにする。あわせて、Eさんは、業務に影響がある一部の部門には切替え期間中はプロキシサーバAが利用可能なことを案内するとともに、⑬恒久対応として設定変更の依頼を事前に行うことにした。
Eさんは、プロキシサーバAのログを定期的に調査し、利用がなくなったことを確認した後に、プロキシサーバAを廃止することにした。
Eさんが検討した可用性向上の検討案は承認され、システム部では可用性向上プロジェクトを開始した。
設問1
[プロキシサーバの利用方法の検討]について答えよ。
表2中の案2の初期設定について、負荷分散を目的として一つのドメイン名に対して複数のIPアドレスを割り当てる方式名を答えよ。
DNSラウンドロビン
表2の案2の初期設定を見ると、proxy.a-sha.co.jp という1つのドメイン名に対して、192.168.1.145(プロキシサーバB)と192.168.2.145(プロキシサーバC)の2つのIPアドレスが登録されていることが分かります。
 石田先生
石田先生このように、1つのFQDNに複数のAレコードを設定し、DNSサーバが名前解決の応答を返す際にIPアドレスの順番を入れ替えることで、アクセス先を分散させる方法をDNSラウンドロビンと呼びます。
DNSラウンドロビンは、専用の負荷分散装置を導入しなくても、DNSサーバの設定だけで複数のサーバに負荷を分散できる手軽な方法です。
今回の案2では、従業員がアクセスするたびにDNSサーバが返すIPアドレスの順序が変わるため、一部の利用者はプロキシサーバBに、別の利用者はプロキシサーバCに接続することになり、平常時から2台のプロキシサーバを有効活用できます。

ただし、この方式には注意点もあるんですよね。
DNSサーバは応答するIPアドレスが指すサーバの稼働状態を監視していないため、障害が発生したサーバのIPアドレスが応答に含まれてしまう可能性があります。
また、DNSキャッシュの影響で、利用者によっては特定のサーバに接続し続けてしまうこともあります。
そのため、本問の本文にもあるように、TTL(有効期限)を短く設定して切替えを早めたり、監視で障害を検知した際にはDNSゾーンファイルから該当IPアドレスを削除したりする運用が重要です。
さらに、DNSだけでなくPACファイルやWPADによる自動切替など、DNS以外の方法と組み合わせることで、より確実な冗長化・可用性向上が実現できます。
このように、案2の設定はDNSラウンドロビンを利用した構成であり、負荷分散と冗長化の両方を実現するための基本的な仕組みとなっています。

このDNSラウンドロビンの可用性向上の観点から見た長所・短所についてもまとめてみましょう。
| 観点 | 長所 | 短所 |
|---|---|---|
| 冗長化 | 複数サーバを並列稼働させることで、片方が故障してももう一方が利用可能。 | DNS自体は死活監視を行わないため、故障サーバのIPが応答に含まれる可能性あり。 |
| 障害時の切替 | TTLを短く設定し、障害検知後に該当IPをゾーンファイルから削除すれば比較的速やかに切替可能。 | TTLを短くしても、既に端末や中間DNSにキャッシュされた情報は即時切替されない場合がある。 |
| 導入コスト | 負荷分散装置や特別なソフト不要で、DNS設定のみで実現できるため低コスト。 | 高度な振り分け機能(接続元地域や負荷状況に応じた制御など)は実現できない。 |
| 平常時の有効活用 | 全サーバを平常時から利用するため、リソースが無駄にならず負荷分散にもなる。 | アクセス分散は単純な順序ローテーションで、実際の負荷状況を考慮できない。 |
| 設定・運用 | DNSサーバ側の設定だけで構成変更可能。 | 障害時のゾーンファイル修正や監視との連動を手動で行うと運用負荷がかかる。 |
本文中の下線①について、ping監視では不十分な理由を40字以内で答えよ。
プロキシサーバのアプリケーションプロセスが停止した場合に検知できないから
ping監視はICMPのエコー要求と応答を利用して行う死活監視の一種で、サーバやネットワーク機器が稼働しているかどうかを確認する際によく使われます。
石田先生しかし、この方法ではあくまでネットワーク層での応答が返ってくるかどうかしか判断できません。
サーバのOSやネットワークインタフェースが正常に動作していれば、アプリケーションが停止していてもping応答は返ってきてしまいます。
今回のケースでは、監視対象がプロキシサーバであり、実際に利用者が必要とするのはHTTPやHTTPS通信を中継するアプリケーションプロセス(プロキシ機能)が正常に動作していることです。
ping監視だけでは、このプロキシプロセスが異常停止していても検知できないため、サービス停止を見逃す可能性があります。
そこで、本文ではTCP監視を追加し、プロキシサーバが待ち受けているポート(HTTPなら80番、HTTPSなら443番など)に対して接続可能かどうかを確認することで、アプリケーションレベルの障害も検知できるようにしています。
石田先生このため、設問の答えは「プロキシサーバのアプリケーションプロセスが停止した場合に検知できないから」となります。
ping監視とTCP監視の違いを比較表でまとめてみましょう。
| 項目 | ping監視(ICMP監視) | TCP監視 |
|---|---|---|
| 監視対象層 | ネットワーク層(ICMPプロトコル) | トランスポート層〜アプリケーション層(TCP接続) |
| 監視方法 | ICMP Echo要求を送り、応答があるか確認 | 指定したポート番号にTCP接続を試み、応答を確認 |
| 検知できる障害 | ネットワーク断、機器停止、OS停止 | ネットワーク断、機器停止、OS停止、アプリケーション停止 |
| 検知できない障害 | アプリケーションプロセスの停止、ポート閉塞 | アプリケーションは起動していてもサービス内部の処理エラーまでは検知できない |
| 導入の容易さ | ほぼ全機器対応、設定が容易 | 対象アプリのポート番号を調査・設定する必要あり |
| 運用負荷 | 低い(シンプルな設定で実行可能) | やや高い(監視対象ごとのポート設定やアプリ依存あり) |
| 本問での評価 | プロキシプロセス停止を検知できず不十分 | プロキシ機能の稼働確認が可能で可用性向上に有効 |
本文中の下線②について、表2の案1の初期設定を対象に、ドメイン名proxy.a-sha.co.jp.の書換え後のIPアドレスを答えよ。
192.168.2.145
表2の案1の初期設定では、proxy.a-sha.co.jp. というドメイン名にはプロキシサーバBのIPアドレス 192.168.1.145 が割り当てられています。
案1の運用方法は、障害発生時にこのAレコードを別のプロキシサーバのIPアドレスへ書き換えることで切り替える方式です。
石田先生設問では、この初期設定から書き換え後のIPアドレスを問われています。
障害対象はプロキシサーバBと想定されているため、利用可能な別系統のサーバはプロキシサーバCです。
プロキシサーバCのIPアドレスは 192.168.2.145 であり、障害発生後は proxy.a-sha.co.jp. のAレコードがこのIPに変更されます。
これにより、従業員のブラウザやサーバはDNS名前解決を通じてプロキシサーバCに接続し、業務を継続できます。
この切替え方式は単純でわかりやすい反面、平常時には1台のサーバしか利用されず、もう1台は待機状態となります。
そのため、リソースの有効活用や負荷分散はできませんが、障害時の切替作業は比較的容易という特徴があります。
石田先生したがって、書き換え後のIPアドレスは 192.168.2.145 となります。
この案1と案2の切替方式の違いについて比較してみましょう。
| 項目 | 案1(待機系切替型) | 案2(平常時負荷分散型) |
|---|---|---|
| 初期設定 | proxy.a-sha.co.jp に1つのIPアドレス(プロキシサーバB)を割当 | proxy.a-sha.co.jp に2つのIPアドレス(B・C)を登録(DNSラウンドロビン) |
| 平常時の利用 | 全トラフィックを1台(B)で処理、もう1台(C)は待機 | トラフィックをB・Cで分散処理 |
| 切替方法 | 障害発生時にDNSのAレコードを書き換えて、待機系のCへ切替 | 障害発生時に障害機のIPアドレスをゾーンから削除し、正常機にのみ振り分け |
| 切替の速さ | DNS書換え後、TTL有効期限経過後に順次切替 | TTL短縮設定+削除により比較的速やかに切替可能 |
| 可用性 | 待機系のCが健全なら障害時でも切替可能 | 2台稼働で平常時から冗長性があり、1台障害時も業務継続がスムーズ |
| リソース活用 | 平常時は1台分の処理能力しか使わない(もう1台は遊休) | 2台とも平常時から稼働し、処理能力を有効活用 |
| 運用負荷 | 切替はシンプルだが、待機系の定期的な動作確認が必要 | DNS設定と監視の連動が必要で、やや複雑 |
| 向いているケース | 障害頻度が低く、構成を簡単に保ちたい場合 | 高負荷環境や平常時から負荷分散・冗長化を行いたい場合 |
本文中の下線③について、TTLの値を小さくする目的を40字以内で答えよ。
キャッシュDNSサーバがキャッシュを保持する時間を短くするため
DNSにおけるTTL(Time To Live)は、DNS応答がキャッシュDNSサーバやクライアント側で保持される有効期限を秒単位で指定する値です。
このTTLが長いと、一度名前解決した結果が長時間キャッシュされるため、ゾーンファイルでIPアドレスを変更しても、キャッシュが有効な間は古い情報が使われ続けてしまうんですよね。
今回のケースでは、プロキシサーバに障害が発生した場合、該当サーバのIPアドレスをDNSゾーンファイルから削除して別の正常なサーバに切り替える運用を行います。
石田先生このときTTLが大きいままだと、既に名前解決してしまった端末やキャッシュDNSサーバが古いIPアドレスを保持し続け、切替が遅延する恐れがあります。
そこで、平常時からTTLを小さく設定しておくことで、キャッシュの保持時間を短くし、ゾーンファイル変更の反映を早めることができます。
これにより、障害発生時に新しいIPアドレスへの切替が迅速に行われ、サービスの可用性向上につながります。
石田先生したがって、設問の答えは「キャッシュDNSサーバがキャッシュを保持する時間を短くするため」となります。
本文中の下線④について、DNSとは異なる方法を20字以内で答えよ。また、その方法の制限事項を、プロキシサーバを利用する側の環境に着目して25字以内で答えよ。
方法:プロキシ自動設定機能を利用する。
制限事項:対応するPCやサーバでしか利用できない。
石田先生下線④で言及されているのは、DNSによる名前解決の切替えとは異なる方法としての「プロキシ自動設定機能(PACファイルやWPAD)」です。
1. 仕組み
PAC(Proxy Auto-Config)ファイルは、JavaScript形式で記述される設定ファイルで、ブラウザやアプリケーションがインターネット接続時に利用するプロキシサーバを動的に選択できます。
ファイル内には「どの宛先にアクセスするときはどのプロキシを使うか、または直接接続するか」という条件分岐を書けます。
WPAD(Web Proxy Auto-Discovery Protocol)は、このPACファイルの場所を自動的に検出させる仕組みです。
これにより、クライアントの設定変更を個別に行わなくても、ネットワーク環境が変われば自動で適切なプロキシ設定を取得できます。
2. DNS方式との違い
DNSによる切替は、名前解決の結果として返すIPアドレスを変更して経路を切替える方式です。
一方PAC/WPAD方式は、クライアント側の動作ロジックでプロキシ選択を行うため、DNSレコードの変更や反映待ちを必要とせず、即時切替が可能です。
例えば、PACファイルに「プロキシBが応答しなければプロキシCへ切り替える」という条件をあらかじめ記述しておけば、障害発生時に利用者は意識せず自動的に別サーバに接続できます。
3. 制限事項
PAC/WPAD方式の弱点は、利用できる環境が限定されることです。
まず、プロキシ自動設定機能はPCやサーバなど、対応ブラウザやOSを持つクライアントでのみ動作します。
ネットワーク機器や特定の組み込み端末では利用できないことが多く、スマートフォンアプリや一部の業務用ソフトもPACを参照しません。
また、WPADによる自動検出はセキュリティ上の理由で無効化されている環境もあり、必ずしも全社的に即時切替が効くわけではありません。
4. 本問での位置づけ
本文では、DNSゾーンファイルの書き換えによる切替と、このPAC/WPAD方式を併用する方針が示されています。
DNSは幅広い環境で利用できる汎用的な方法ですが反映に時間がかかるため、即時性が必要なクライアント環境ではPACを活用し、対応していない機器や環境ではDNSによる切替を使うという棲み分けを行うことで、全体的な可用性と切替スピードを両立させています。
設問2
[マルチホーム接続]について答えよ。
本文中及び表3中の( a )~( f )に入れる適切な字句を答えよ。
a:AS
b:ピア
c:UPDATE
d:KEEPALIVE
e:ルーティングテーブル
f:大きい
(a)AS(Autonomous System)
BGPは、異なる管理ドメイン同士で経路をやり取りするための外部ルーティングプロトコルです。
ここでいう管理ドメインがAS(自律システム)であり、各ASには一意のAS番号が割り当てられます。
OSPFやIS-ISのようなIGPが「AS内部(単一管理ドメイン内)」の収束を担うのに対し、BGPは「AS間(対外)」の到達性をやり取りする役割を持ちます。
本問の文脈では、D社閉域NWとA社の境界でeBGPを使い、A社内部のBGPではiBGPを使う構成になっています。
(b)ピア(BGPピア/ネイバー)
BGPで直接経路情報を交換する相手ルータをピア(peer, neighbor)と呼びます。ピア関係はTCP/179で明示的に確立する必要があり、単にL2やL3で隣接しているだけでは成立しません。
ピアには以下の2種類があります。
- iBGPピア:同一AS内で結び、外部から受信した経路をAS内に配布します。
特にiBGPではnext-hop-self設定などの調整が重要であり、本問でもR11—R13間にiBGP+next-hop-selfを入れています。 - eBGPピア:AS番号が異なる相手と結び、対外ルーティングを行います。
(c)UPDATE(経路広告・撤回メッセージ)
BGPで新規経路の広告や経路撤回を行うメッセージがUPDATEです。
このUPDATEメッセージには、AS_PATH、NEXT_HOP、LOCAL_PREF、MED、COMMUNITYなどのパスアトリビュートが含まれます。
今回のシナリオでは、AS内部でどの出口を優先するかをLOCAL_PREFで表現し、UPDATEメッセージを通じてAS内の経路選択を統一します。
(d)KEEPALIVE(セッション維持メッセージ)
BGPセッションを維持・監視するために定期的に送信するのがKEEPALIVEメッセージです。
相手から一定時間(Hold Time)内にKEEPALIVEやUPDATEが届かない場合、そのピアとのセッションはダウンと判断されます。
多くの実装では、Keepalive間隔は60秒、Hold Timeは180秒がデフォルトです。
障害検知を早めたい場合はBFD(Bidirectional Forwarding Detection)と組み合わせる方法もあります。
BFDは、ルータやスイッチ間のリンク障害を非常に高速に検知するためのプロトコルです。OSPFやBGPのようなルーティングプロトコルは標準で死活監視の機能を持っていますが、障害検出の間隔は数秒~数十秒と遅くなることがあります。これではミッションクリティカルなシステムでは不十分です。
そこでBFDを併用することで、ミリ秒単位(例:50ms〜数百ms)で障害を検知し、ルーティングプロトコルに即座に通知して経路の切替えを促すことができます。
[主な特徴]
- プロトコル非依存:OSPF、BGP、IS-IS、静的ルートなど、どのルーティング手法とも組み合わせて利用できます。
- 軽量設計:小さい制御メッセージを定期的にやり取りするだけなので、機器負荷が少ない。
- 双方向監視:その名の通り、双方向のパスで疎通を確認するため、片方向障害も検知可能です。
(e)ルーティングテーブル(RIB/FIBへの反映)
BGPは、受信した経路情報をBGPテーブルに保持し、最適経路アルゴリズムで経路を1本に絞ります。
その結果をルーティングテーブル(RIB)に反映し、さらに転送テーブル(FIB)にインストールしてパケット転送に利用します。
ポイントは、BGPで複数の経路を学習しても、実際に使うのは選ばれた1経路だけであるということです。
この選択にLOCAL_PREFなどの優先度が影響します。
(f)大きい(LOCAL_PREFは値が大きい方を優先)
LOCAL_PREFは、同一AS内でどの出口を使うかの優先度を示す属性で、値が大きいほど優先されます。
この属性はAS外には伝搬せず、AS内部だけで有効です。
そのため、AS内の全ルータで出口選択を統一することができます。
補足として、外部からどの入口で受信してほしいかを制御する場合は、LOCAL_PREFではなくMEDやAS_PATHプリペンディングなど、対外的に伝わる属性を利用します。
BGPメッセージ4種類をまとめておきましょう。
| メッセージ種類 | 主な役割 | 送信タイミング | 補足説明 |
|---|---|---|---|
| OPEN | ピアとのBGPセッションを確立するための初期交渉を行います。 | セッション開始時のみ送信 | AS番号、BGPバージョン、Hold Time、BGP識別子(Router ID)などを交換します。パラメータ不一致やエラーがある場合はNOTIFICATIONを返します。 |
| UPDATE | 経路情報の広告や撤回を行います。 | 経路が新たに学習された時や不要になった時 | AS_PATH、NEXT_HOP、LOCAL_PREF、MEDなどのパスアトリビュートを含みます。BGPの経路制御の中核となるメッセージです。 |
| KEEPALIVE | BGPセッションの維持と死活確認を行います。 | 定期的(既定は60秒ごと)に送信 | 更新情報がない場合でも送信します。相手からのKEEPALIVEやUPDATEがHold Time内に来なければセッション断とみなします。BFDと併用することで検知速度を向上できます。 |
| NOTIFICATION | エラー発生時に相手に通知し、セッションを終了します。 | エラー検出時 | 不正なメッセージやパラメータ不一致、セッション維持不能などの理由をコードで通知します。送信後はBGPセッションが切断されます。 |
本文中の下線⑤について、next-hop-self設定を行うと、iBGPで広告する経路情報のネクストホップのIPアドレスには何が設定されるか。15字以内で答えよ。
自身のIPアドレス
BGPでは、経路情報を広告する際にネクストホップ(Next Hop)として、その経路を通るために次に到達すべきルータのIPアドレスをパスアトリビュートに含めます。
通常、iBGPでは外部(eBGP)から受信した経路情報をそのまま別のiBGPピアに広告すると、ネクストホップの値は外部ピアのIPアドレスのままになります。
この場合、受信側のルータがその外部ピアに直接到達できなければ、経路は使えません。
この問題を解消するために用いられるのがnext-hop-self設定です。
これを有効にすると、iBGPで広告する際にネクストホップを自分自身のIPアドレスに書き換えます。
結果として、受信側は必ず自分が直接到達できる相手をネクストホップとして認識できるため、経路が有効になります。
今回のケースでは、R11とR13の間でiBGPを張り、外部経路をAS内部に伝える際にnext-hop-selfを設定することで、内部ルータが到達可能なネクストホップに置き換えて運用する設計になっています。
石田先生したがって答えは「自身のIPアドレス」となります。
表3について、BGPピア間で定期的にやり取りされるメッセージを一つ選び、タイプで答えよ。また、そのメッセージが一定時間受信できなくなるとどのような動作をするか。30字以内で答えよ。
タイプ:4
動作:BGP接続を切断し、経路情報がクリアされる。
表3に示されるBGPメッセージのうち、BGPピア間で定期的にやり取りされるのはKEEPALIVEメッセージです。
これはBGPのメッセージタイプ番号で4に該当します。
KEEPALIVEは、BGPセッションの維持と死活確認のために定期的に送信されます。
デフォルトでは60秒ごとに送られ、相手からのKEEPALIVEやUPDATEがHold Time(通常180秒)内に届かない場合、そのピアとのセッションはダウンと判断されます。
セッションがダウンすると、そのピア経由で得ていた経路情報はすべてルーティングテーブルから削除(クリア)されます。
これにより、無効な経路を使い続けることを防ぎます。
本文中の下線⑥について、BGPの導入を行った後にVRRPの導入を行うべき理由を、R13が何らかの理由でVRRPマスターになったときのR13の経路情報の状態を想定し、50字以内で答えよ。
VRRPマスターになったR13が経路情報を保持していないと受信したパケットを転送できないから
石田先生本問では、BGP導入とVRRP導入の順序が問われています。
VRRPはルータの冗長化プロトコルで、仮想IPアドレスを共用し、マスターとなったルータがその仮想IP宛のトラフィックを処理します。
今回の構成では、R11とR13がVRRPでペアを組み、FW10がデフォルトゲートウェイとしてVRRPの仮想IPを参照します。
もしBGPより先にVRRPを導入してしまうと、経路情報をまだ保持していないR13が、何らかの理由でマスターになってしまう可能性があります。
この場合、FW10からR13にパケットは届いても、R13は宛先に関する経路を知らないため、パケットを正しく転送できません。
そのため、まずBGPを導入して全ルータが適切な経路情報を保持できる状態にしてからVRRPを設定する必要があります。
これにより、マスターがどちらになっても、受信したパケットを確実に転送できる状態が保証されます。
石田先生したがって答えは「VRRPマスターになったR13が経路情報を保持していないと受信したパケットを転送できないから」となります。
表4中の下線⑦について、pingコマンドの試験で確認すべき内容を20字以内で答えよ。また、pingコマンドの試験で確認すべき送信元と宛先の組合せを二つ挙げ、図3中の機器名で答えよ。
確認すべき内容:パケットロスが発生しないこと
①「送信元:R13 宛先:FW10」又は「送信元:FW10 宛先:R13」又は「送信元:R13 宛先:R11」又は「送信元:R11 宛先:R13」
②「送信元:R13 宛先:R14」又は「送信元:R14 宛先:R13」
確認すべき内容
石田先生この問題は、受験生が非常に間違えやすいポイントを含んでいます。
ping試験といえば多くの参考書や実務経験では「応答があるか」を確認する場面が多いため、そのまま解答欄に「応答があること」と書きたくなるのは自然です。
しかし本問で正解となるのは「パケットロスが発生しないこと」であり、この点を導き出すのは容易ではありません。
ここで重要なのは、問題の背景が「可用性向上策を導入したシステムでの障害試験」だということです。
障害を発生させても、VRRPやBGPによる経路切替によって通信は継続できることが前提になっています。
つまり「応答がある」ことは当たり前であり、それだけを確認するのでは不十分なのですね。
本当に検証すべきは、切替え中に通信が途切れず継続したか、すなわちパケットロスが発生しなかったかという点なのです。
受験生にとって難しいのは、普段のping利用イメージから一歩踏み出して「切替え過程の継続性確認」を意識できるかどうかです。
多くの人が「応答があること」と答えてしまうのは、ping=死活確認という基本イメージに引きずられてしまうからです。
石田先生ここで問われているのは、単なる疎通ではなく、高可用性設計の有効性をどう検証するかという観点であり、そこに気づけるかどうかが合否を分けます。
したがって、正解である「パケットロスが発生しないこと」は、ただの疎通確認よりも高度な検証観点であり、この問題の難しさはまさに「いつもの答え方では不十分だ」と切り替えて考えられるかどうかにあります。
①(送信元:R13⇔宛先:FW10/R11)
この組の狙いはデフォルトゲートウェイ側(社内側)経路の健全性を確認することです。
FW10はVRRPの仮想IPをネクストホップに静的経路で向けます。
R13⇔R11:VRRPペア間およびiBGP/スタティック連携の内側疎通を確認します。ここでロスがあると、VRRPトラッキングや内部リンク、フィルタ設定に起因する不整合(例:片系のみ応答)が疑われます。
この①でロスがなければ、「端末側GW〜VRRP〜FW10」という社内側の足回りは問題ないと判断できます。
R13⇔FW10:VRRPマスターがどちらであっても、FW10から見た仮想IP解決(ARP)と、FW10—VRRP実体間のL2/L3疎通が正常であることを検証できます。R13がマスター化した局面でもロスなく応答すれば、VRRP切替の成否と社内→境界までの経路が確認できます。
②(送信元:R13⇔宛先:R14)
この組の狙いは上流(閉域NW側)経路の健全性と冗長経路の可用性を確認することです。
R13—R14はeBGPピアで、障害時には既設線→増設線(または逆)へトラフィックが切り替わります。
ここでロスや高い揺らぎが出る場合、BGPは成立していても物理層・QoS・ACL(ICMP抑制)・中間区間の不調が疑われます。
切替シナリオではこの経路がボトルネックになりやすいため、①とは独立に②を実施しておくと、社内側か上流側かの切り分けが容易になります。
この②でロスがなければ、「VRRPの先(上流)〜閉域NW〜対向」という外向きの足回りが健全と判断できます。
R13⇔R14でロスがないことは、eBGPセッション維持(KEEPALIVE受信)、ネクストホップ到達性、および閉域NW側リンク品質が良好であることの指標になります。
表4中の下線⑧について、R11及びR12では静的経路制御の経路情報を削除することで同じ宛先ネットワークのBGPの経路情報が有効になる。その理由を40字以内で答えよ。
経路情報は、BGPと比較して静的経路制御の方が優先されるから
ルータの経路選択には管理距離(Administrative Distance, AD)と呼ばれる優先度があります。
管理距離が小さい経路ほど優先され、同じ宛先ネットワークへの複数の経路が存在する場合、最も管理距離が低い経路がルーティングテーブルに採用されます。
一般的な設定では、静的経路制御の管理距離は「1」と非常に低く、BGPの管理距離はiBGPで「200」、eBGPで「20」です。
つまり、同じ宛先ネットワークに静的経路とBGP経路が両方存在する場合、静的経路が必ず優先されます。
今回のR11およびR12では、もともと宛先ネットワークに対する静的経路が設定されているため、BGPで学習した経路は存在していても無効化されてしまいます。
そこで、静的経路情報を削除することで、管理距離の比較においてBGP経路が唯一の候補となり、ルーティングテーブルに反映されるようになります。
石田先生したがって、答えは「経路情報は、BGPと比較して静的経路制御の方が優先されるから」となります。
管理距離の優先順位についてまとめてみましょう。
| 経路の種類 | 管理距離(AD値) | 優先度の位置づけ | 補足説明 |
|---|---|---|---|
| 直結(Directly Connected) | 0 | 最優先 | 物理的に接続されているネットワーク。必ず最優先で採用されます。 |
| スタティック(Static Route) | 1 | 非常に高い | 手動で設定した経路。BGPやOSPFよりも優先されます。 |
| eBGP(外部BGP) | 20 | 高い | 異なるAS間での経路交換。スタティックがなければ最優先に採用されます。 |
| OSPF(Open Shortest Path First) | 110 | 中程度 | IGPの代表例。広く利用されるリンクステート型プロトコル。 |
| IS-IS(Intermediate System to Intermediate System) | 115 | 中程度 | OSPFと同様のリンクステート型IGP。 |
| RIP(Routing Information Protocol) | 120 | 低い | 古典的なIGP。ホップ数ベースで経路選択します。 |
| iBGP(内部BGP) | 200 | 非常に低い | 同一AS内での経路交換。多くの場合、IGP経路より優先度が低い。 |
| 未知の経路 | 255 | 使用不可 | ルータが到達不能と判断する経路。 |
- 数値が小さいほど優先度が高いため、同一宛先に複数の経路がある場合は、AD値の最も小さいものがルーティングテーブルに採用されます。
- 今回のR11・R12では、スタティック(AD=1)がBGP(eBGP=20/iBGP=200)より優先されてしまうため、BGP経路を使うには静的経路を削除する必要があるのです。
本文中の下線⑨について、想定する障害を六つ挙げ、それぞれの障害発生箇所を答えよ。ただし、R12とR14についてはD社で障害試験実施済みとする。
①R11
②R13
③R11とR12とを接続する回線
④R13とR14とを接続する回線
⑤R11とL2SW10とを接続する回線
⑥R13とL2SW10とを接続する回線
① R11の障害
R11は既設線側のeBGPルータで、通常はR13とVRRPで冗長構成を取っています。
R11が停止すると、VRRPがR13をマスター化し、社内から外部への通信はすべてR13経由で増設線側へ流れます。
この切替えが正しく行われているかを確認するためには、まずVRRPの状態遷移を監視し、R13がマスターになったことを確認します。
続いて、R13が上流とのBGPセッションを維持し、経路情報が正しくルーティングテーブルに反映されているかを確認します。
最後にFW10からR13へのping試験を行い、切替え後もパケットロスが発生していないことを確認します。
② R13の障害
R13は増設線側のeBGPルータで、R11と同様にVRRPペアを構成しています。
R13が停止すると、VRRPがR11をマスター化し、既設線経路が唯一の経路として利用されます。
この際には、R11が上流とのBGPセッションを維持しているか、経路情報がルーティングテーブルに正しく反映されているかを確認します。
さらにFW10からR11へのpingを行い、通信断やパケットロスが発生していないことを検証します。
これにより、増設線ルータが停止しても既設線経路で業務が継続できることを確認できます。
③ R11—R12間の回線障害(既設線)
既設線側の閉域NW接続回線を切断すると、R11経由の上流経路が失われます。
この場合、BGPはR13—R14経由の増設線ルートに収束するはずです。
試験では、まずR11—R12間のBGPピアがダウンしたことを確認し、その結果R11経路がルーティングテーブルから削除され、R13経路が唯一残っていることを確認します。
その後、FW10経由でR13からR14へのping試験を行い、切替え経路でもパケットロスがないことを確かめます。
④ R13—R14間の回線障害(増設線)
増設線側の閉域NW接続回線を切断すると、R13経由の上流経路が失われます。
この場合はBGPが既設線側(R11—R12経由)の経路に収束します。
試験では、まずR13—R14間のBGPピアがダウンしたことを確認し、R13経路がルーティングテーブルから削除されてR11経路が唯一残ることを確認します。
そのうえで、FW10経由でR11からR12へのpingを行い、切替え後の通信経路が問題なく動作していることを確認します。
⑤ R11—L2SW10間の回線障害(社内側)
R11の社内側リンクが切断された場合、R11は上流には到達できても社内との通信ができなくなります。
この場合、VRRPのトラッキング機能が動作し、R13がマスター化するはずです。
試験では、まずVRRPの状態遷移を確認してR13がマスターになったことを確認します。
次に、FW10からR13へのpingを行い、切替え後も社内から外部への通信が維持されていることを確認します。
⑥ R13—L2SW10間の回線障害(社内側)
R13の社内側リンクが切断された場合も同様に、VRRPトラッキングが働き、R11がマスター化します。
試験では、まずVRRPの状態を確認してR11がマスターになったことを確認します。
その後、FW10からR11へのpingを行い、社内から外部への通信が継続できていることを検証します。
こうすることで、社内側リンク障害でも経路が確実に切替わることを確認できます。
設問3
[インターネット接続の切替え]について答えよ。
本文中の下線⑩について、D社閉域NWの設定変更より前にFW10のデフォルトルートの設定変更を行うとどのような状況になるか。25字以内で答えよ。
ルーティングのループが発生する。
下線⑩では、インターネット接続を本社経由からD社閉域NW経由に切り替える作業順序について触れています。
ここで重要なのは、FW10のデフォルトルート変更とD社閉域NW側の設定変更を同時、もしくは正しい順序で行う必要があるという点です。
もしD社閉域NWの設定変更よりも前にFW10のデフォルトルートを変更してしまうと、FW10からのインターネット向けトラフィックがD社閉域NWへ送られます。
しかし、閉域NW側のルータはまだ新しい経路設定を反映していないため、受け取ったパケットを再びFW10へ送り返してしまう可能性があります。
これにより、FW10と閉域NWルータの間でパケットが行ったり来たりするルーティングループが発生します。
このループ状態になると、宛先に到達できないだけでなく、リンクや機器に不要なトラフィック負荷がかかり、ネットワーク全体の通信品質が低下します。
そのため、順序は必ず「閉域NW設定変更 → FW10のデフォルトルート変更」とし、経路が一方向に正しく通る状態を先に作ることが重要です。
石田先生したがって答えは「ルーティングのループが発生する。」となります。
本文中の下線⑪について、業務に影響が発生する理由を20字以内で答えよ。
送信元IPアドレスが変わるから
下線⑪の場面では、インターネット接続経路を本社経由からD社閉域NW経由(FW40)へ切り替える計画があります。
この切替えによって、社外に見える送信元IPアドレスが、従来のFW10のグローバルIPからFW40のグローバルIPへ変わります。
一部の部門では、利用しているSaaSが送信元IPアドレスによってアクセス制限を行っているため、このIPアドレスが変更されると、外部サービス側で通信が拒否され、業務アプリケーションへのアクセスができなくなります。
これが「業務に影響が発生する理由」です。
そのため、影響を受ける部門には事前に案内し、必要に応じてSaaS提供者側で新しいIPアドレスを許可設定してもらうか、切替期間中は従来経路(FW10経由)を利用できるようにする必要があります。
石田先生したがって答えは「送信元IPアドレスが変わるから」となります。
本文中の下線⑫について、FW10にどのようなポリシーベースルーティング設定が必要か。70字以内で答えよ。
送信元IPアドレスがプロキシサーバAで宛先IPアドレスがインターネットであった場合にネクストホップをR10とする設定
下線⑫の場面では、インターネット接続切替期間中、基本的には全ての通信を新しい経路(FW40経由)に流しますが、特定の例外として「プロキシサーバAからの通信だけは既存のR10経由」に残す必要があります。
これは、影響を受ける部門がプロキシAを経由して利用するSaaSが、送信元IP制限により新しい出口(FW40のIP)ではアクセスできなくなるためです。
このように、特定条件(送信元や宛先など)に基づいてルーティング経路を振り分けるためには、ポリシーベースルーティング(PBR)を用います。
PBRは、ルーティングテーブルの最適経路選択ではなく、事前に設定したポリシー条件に合致した場合に、指定したネクストホップへ強制的に転送します。
今回必要なのは、FW10上で以下の条件を満たすパケットに対してネクストホップをR10に設定するポリシーです。
- 送信元IPアドレス:プロキシサーバA(例えば192.168.x.xなど)
- 宛先IPアドレス:インターネット向け(RFC1918以外、または明示的に0.0.0.0/0にマッチ)
これにより、プロキシA発の外部通信は従来通りR10へ送られ、それ以外の通信は新しい経路(FW40)へ流れます。
これを実装することで、切替期間中でも影響を受ける部門は業務を継続でき、他の通信は新しい構成を利用できます。
石田先生したがって答えは「送信元IPアドレスがプロキシサーバAで宛先IPアドレスがインターネットであった場合にネクストホップをR10とする設定」となります。
本文中の下線⑬について、どのような設定変更を依頼すればよいか。40字以内で答えよ。
SaaSの送信元IPアドレスによるアクセス制限の設定変更
下線⑬の場面は、インターネット接続経路の切替えに伴い、送信元IPアドレスが変更されることへの恒久対応を検討しています。
A社の一部部門では利用するSaaSが送信元IPアドレスによるアクセス制限(IPアローリスト)を実施しているため、切替後にFW40経由で通信すると、新しいグローバルIPがSaaS側で許可されていない場合はアクセスが拒否されます。
この影響を恒久的に解消するには、SaaSの管理者や提供ベンダーに対して、新しいFW40のグローバルIPアドレスをアクセス許可リストに追加登録するよう依頼する必要があります。
これにより、切替後も従来と同様に認証や通信が行えるようになります。
実務的には以下のような依頼内容になります。
- 対象SaaS名とアカウント情報を明示
- 新旧IPアドレス(旧:FW10、 新:FW40)を併記
- 適用予定日を明確にして、切替前に設定反映してもらう
こうした事前設定により、切替当日にSaaSアクセス不能になるリスクを防止できます。
石田先生したがって答えは「SaaSの送信元IPアドレスによるアクセス制限の設定変更」となります。


